Recent Results
Panayiotis Danassis has developed an algorithm called Altruistic Matching Heuristic (ALMA) that allows for the first time, to solve large-scale distributed resource allocation problems in constant time. It was presented in a series of papers at AAMAS 2019, 2020 and 2022, and IJCAI-2019 and 2021.
Generative natural language models can be used to explain the actions of AI systems. Diego Antognini has shown how explanations of product recommendations generated through personalized language models can be used for critiquing and thus influencing the recommendations. The work has been published at the IJCAI and Recsys conferences in 2021.
Aleksei Triastcyn has developed a new privacy definition for machine learning, called Bayesian Differential Privacy. It provides more meaningful bounds for privacy-preservation in machine learning than the general definition of Differential Privacy. The concept was highlighted in a recent paper at the 37th International Conference on Machine Learning (ICML 2020) and generated a lot of interest.
Recent News

22.08.2023 – AI lab paper wins best paper award
At the IJCAI-2023 workshop on Trustworthy Federated Learning, the paper:
“Privacy-Preserving Data Quality Evaluation in Federated Learning Using Influence Approximation” by Ljubomir Rokvic, Panayiotis Danassis and Boi Faltings
Job opportunities
Unfortunately, as Prof. Faltings is close to retirement age, there are no openings for new Ph.D. students at LIA.
LIA co-organized events
IJCAI 2022 Workshop on Federated Learning
Location
How to reach the LIA using public transport
From all international airports in Switzerland, you can easily reach Lausanne by train. From Geneva, there are at least 3 trains for Lausanne every hour, the journey takes between 44′ and 1h. Trains from Zürich Airport take between 2h40 and 3h10. Find timetables at the Swiss Railway company’s web-site.
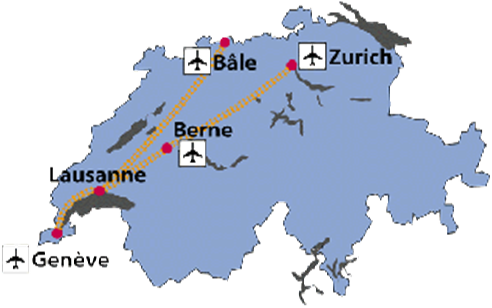
A metro station is located just in front of the train station. Take the metro uphill, in the direction calledFile Edit View Insert Format Tools Table “Centre-Ville”, until the end of the line (just 3′). There, transfer to what is called the TSOL (departures every 10′ on work days). Get off at the stop called EPFL. The journey from the railway station to the EPFL takes approx. 30′.
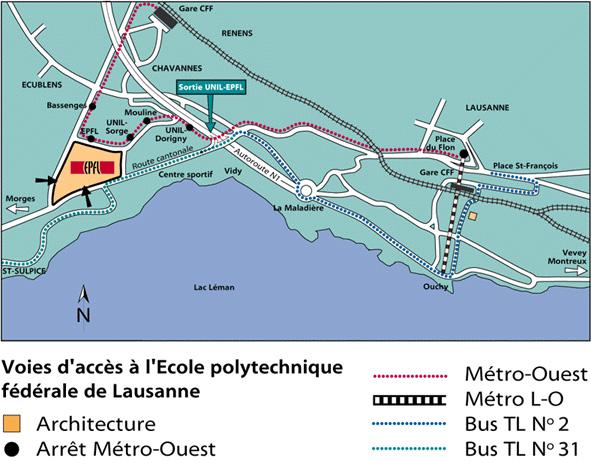
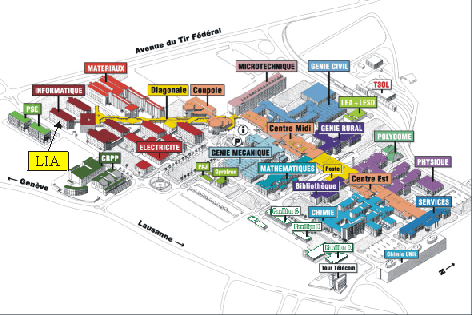
The LIA is located in the south-west corner of the EPFL site, on the second floor of the building INR.
How to reach the LIA by car
-
From Geneva, approx. 10 kms before Lausanne, you will have the choice between two directions. Take “LAUSANNE SUD”. Then follow the EPFL exit. You are on the “Route du Lac”. There are two ways in for EPFL. Take the second, which is located just before a traffic light, then follow the blue parking icons. Avoid parking on the green places, they are reserved for students and employees.
-
From Bern, you have to take the direction Geneva until you find a sign indicating “LAUSANNE SUD”. Then proceed as above. For further orientation consult the map of Lausanne.
History
The Artificial Intelligence Laboratory (LIA) was founded in 1987 by Prof. Boi Faltings, in the Computer Science Department at the Swiss Federal Institute of Technology in Lausanne (EPFL). At this time the lab was most active in fields like model-based and qualitative reasoning. Kefeng Hua, Kun Sun, Esther Gelle and Monika Lundell developed novel techniques for qualitative modelling and its application in engineering design.
In the 1990s more expertise in constraint satisfaction and case-based reasoning were developed. The lab made several fundamental contributions to constraint satisfaction with continuous variables and abstraction and reformulation techniques for constraints, notably by Berthe Choueiry, Christian Frei and Steve Willmott. These were applied with much success to resource allocation and routing problems, and later lead naturally to work in software agents. A sequence of Ph.D. theses by Marius Silaghi, Adrian Petcu, Thomas Léauté and Brammert Ottens developed the topic of constraint satisfaction in distributed environments.
A more recent development along this line considered coordination schemes for massive multi-agent systems with only limited communication. Following on the thesis of Ludek Cigler, which established a heuristic for multi-agent resource allocation with logarithmic convergence time, Panayiotis Danassis developed a more general heuristic with an altruistic backoff scheme called ALMA. Under certain realistic assumptions, that algorithm is the first to solve multi-agent coordination problems such as meeting scheduling in parallel constant time.
Marc Torrens and Paolo Viappiani developed several technologies relevant to the world-wide web, in particular for preference-based search, recommender systems and reputation systems. This was later taken up by Florent Garcin, who worked with post-doctoral fellow Christos Dimitrakakis to develop one of the first session-based recommendation systems based on context trees. The system showed impressive reliability and performance on live implementations at sites of Le Point and Swissinfo.
Another line of work investigated game-theoretic mechanisms for eliciting truthful information. Several Ph.D. theses by Radu Jurca, Goran Radanovic and Naman Goel led to a number of fundamental mechanisms, tutorials and a book on the topic. Florent Garcin showed how these novel mechanisms could yield more reliable prediction markets, in particular by operating a public platform called Swissnoise.
Since 1996, a research group led by Dr. Martin Rajman <https://www.epfl.ch/labs/lia/people/martin-rajman/> is also attached to LIA. Its work includes advances in text mining and knowledge extraction techniques. Besides this, under the guidance of post-doctoral researcher Claudiu Musat, in the 2010s we researched sentiment analysis using crowdsourced knowledge bases.
In 1997, Iconomic Systems S.A. was founded by Boi Faltings and Christian Frei with the goal of commercializing a new network routing technique. It was relaunched in 1999 to develop innovative software for travel e-commerce, backed by 3i and Partners Group, and sold in 2001. This started the virus that has led to 4 other successful startup companies founded or co-founded by former members of LIA and based at least in part on results of the laboratory:
- Strands (Marc Torrens, 2003), is a company based in Corvallis, Oregon, focussed on recommendation technology,
- NexThink (Pedro Bados, Boi Faltings, 2004), based in the PSE, produces solutions for information security,
- 3Scale Networks SL (Steven Willmott, 2007), based in Barcelona, provides new technologies for web service contracting, and
- Prediggo (Vincent Schickel, Boi Faltings, 2008) sells recommendation tools based on ontology filtering.